
Việc xây dựng một hệ thống Retrieval-Augmented Generation (RAG) hiệu quả không hề đơn giản – đặc biệt khi bạn là một startup nhỏ hoặc lập trình viên độc lập, vừa phải chạy deadline vừa phải “cân đo ngân sách”.
Trong bài viết này, tôi sẽ chia sẻ cách mình đã triển khai một pipeline RAG hiệu quả với:
- 🔢 Dữ liệu < 1000MB (gồm văn bản + hình ảnh có biểu đồ)
- 🌐 Ngôn ngữ chính là tiếng Việt
- 💵 Ngân sách API dưới 50 USD/tháng
- ⏱️ Thời gian triển khai hạn chế (từ 5 đến 15 tuần)
Hy vọng bài viết này sẽ giúp bạn có cái nhìn tổng thể và chọn được các công cụ phù hợp nhất cho nhu cầu của mình.
📌 Mục lục:
- RAG là gì?
- Quy trình xử lý dữ liệu: ETL (Extract – Transform – Load)
- Lựa chọn các mô hình, loại CSDL, giải pháp lưu trữ, nền tảng hosting
- Tổng kết kiến trúc đề xuất và kết luận
🔄 RAG là gì?
RAG là viết tắt của Retrieval-Augmented Generation, một kỹ thuật giúp cải thiện kết quả đầu ra của các mô hình ngôn ngữ lớn (LLM) bằng cách cung cấp ngữ cảnh phù hợp được truy xuất từ cơ sở dữ liệu vector.

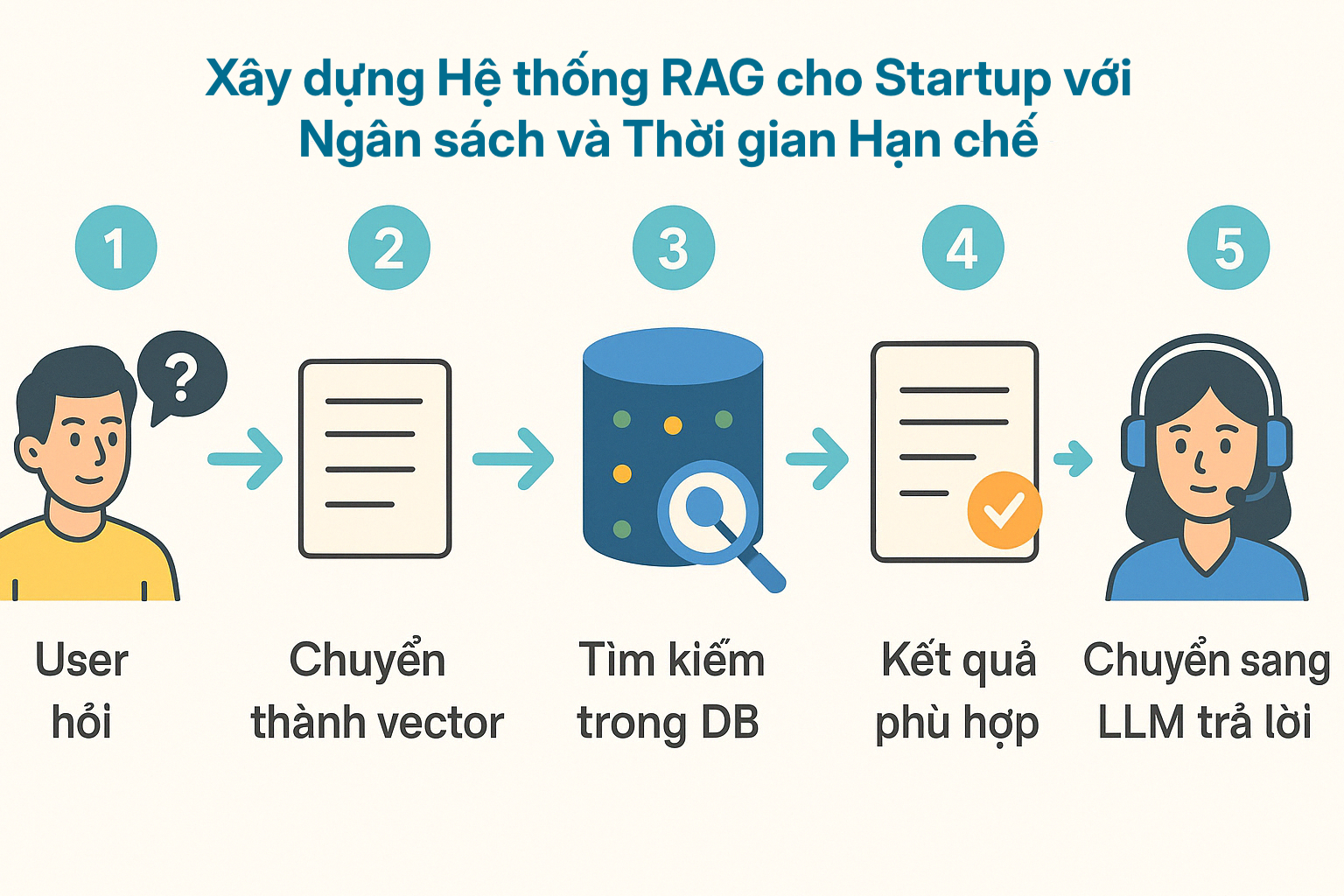
Hình 1: sơ đồ quy trình xử lý của hệ thống RAG
Quy trình RAG cơ bản như sau:
- Người dùng đặt câu hỏi.
- Câu hỏi được chuyển đổi thành vector.
- Hệ thống tìm kiếm các vector tương tự trong cơ sở dữ liệu.
- Các kết quả phù hợp nhất được truy xuất.
- Các kết quả này được đưa vào LLM để tạo ra câu trả lời.
Để xây dựng hệ thống này, bạn cần:
- Mô hình nhúng (Embedding model): ví dụ mô hình embed-multilingual-v3.0 của Cohere
- Cơ sở dữ liệu vector: ví dụ vector db FAISS của Meta
- LLM: ví dụ mô hình GPT-4o
- Hệ thống xử lý dữ liệu ETL: ví dụ: dữ liệu phi cấu trúc PDF, bảng biểu, biểu đồ, hình ảnh, v.v…
📥 Quy trình xử lý dữ liệu: ETL (Extract – Transform – Load)
Các bước xử lý dữ liệu ETL:
- Extract (Trích xuất): Lấy dữ liệu từ nhiều nguồn khác nhau (lưu trữ cục bộ, cloud, cơ sở dữ liệu, CDN, web scraping, API) và nhiều định dạng (PDF, hình ảnh, video, âm thanh, văn bản).
- Transform (Chuyển đổi): Biến dữ liệu thô thành các đoạn có ý nghĩa về ngữ nghĩa. Với dữ liệu phi cấu trúc, bạn cần:
- PDF: trích xuất văn bản và cấu trúc.
- Hình ảnh: phát hiện văn bản, sơ đồ, bảng biểu.
- Video: chuyển đổi âm thanh thành văn bản STT (Speech-to-Text).
- Làm sạch và phân chia nội dung hợp lý (phân đoạn theo token hoặc ngữ nghĩa).
Các công cụ như LangChain , LlamaParse, Unstructured và Chonkie có thể hỗ trợ quá trình ETL này.
- Load (Nạp): Lưu trữ vector vào cơ sở dữ liệu như FAISS, Milvus, QDrant hoặc Neo4j, chú ý hiệu năng, chi phí và khả năng hỗ trợ đa người dùng.
Truy xuất dữ liệu (Retrieval):
Sau khi hoàn thành ETL, cơ sở dữ liệu của bạn đã sẵn sàng hoạt động.
- Chuyển đổi truy vấn thành vector
- Truy xuất các đoạn phù hợp nhất
- Tinh chỉnh hàm tương tự (similarity functions)
- Xem xét các phương pháp tìm kiếm kết hợp (metadata + embeddings)
- Tái xếp hạng với các công cụ như Cohere Rerank

Hình 2: sơ đồ quy trình xử lý dữ liệu thành vector embeddings
🧩 Loại dữ liệu
- Cấu trúc: CSV, Excel, JSON…
- Phi cấu trúc: PDF, hình ảnh (biểu đồ, sơ đồ), video, văn bản thô
Trong thực tế, 80% dữ liệu phi cấu trúc thường vô dụng — việc lọc ra 20% giá trị thực rất quan trọng.
🔧 Các bước ETL
| Bước | Công cụ gợi ý | Mô tả |
| Extract | Local, API, web | Thu thập dữ liệu từ nhiều nguồn khác nhau |
| Transform | Unstructured, LlamaParse, Chonkie, OCR, Whisper | Trích xuất, xử lý ngôn ngữ tự nhiên, phân đoạn |
| Load | FAISS, QDrant, Milvus (Zilliz) | Nhúng vector vào cơ sở dữ liệu vector phù hợp |
✍️ Lựa chọn các mô hình, loại CSDL, giải pháp lưu trữ, nền tảng hosting
🧠 Chọn mô hình Text Embedding
| Tiêu chí | OpenAI (text-embedding-3-small) | Cohere (embed-multilingual-v3.0) |
| Ngôn ngữ tiếng Việt | Ổn định | Tốt hơn, hỗ trợ đa ngôn ngữ |
| Chi phí | ~$0.00002/1K tokens | Có free tier (~100K tokens/tháng) |
| Dễ dùng | Có API đơn giản | Có API đơn giản |
✅ Khuyến nghị:
Với tiếng Việt và ngân sách hạn chế → Cohere v3.0 Multilingual là lựa chọn rất hợp lý.
🖼️ Chọn mô hình Image Embedding (cho biểu đồ, hình vẽ)
Với các tệp chứa hình ảnh hoặc biểu đồ, bạn có thể dùng mô hình CLIP (OpenAI) để tạo vector embedding từ hình ảnh.
| Công cụ | Ưu điểm |
| CLIP ViT-B/32 (via HuggingFace) | Miễn phí, dễ chạy cục bộ |
| CLIP-as-service (Jina AI) | Có sẵn API cloud |
✅ Gợi ý: Dùng CLIP + sentence-transformers để kết hợp embedding ảnh + text vào cùng vector space.
📦 Chọn Vector Database (Vector DB)
FAISS vs Milvus (Zilliz Cloud)
| Tiêu chí | FAISS (local) | Milvus (Zilliz Cloud) |
| Dễ triển khai | ✅ Rất dễ, chạy trên máy | ⚠️ Cần Docker/K8s hoặc Zilliz |
| Hỗ trợ filter | ❌ Không | ✅ Có filter theo metadata |
| Tốc độ | Nhanh | rất nhanh |
| Chi phí | Miễn phí | Có gói miễn phí từ Zilliz |
✅ Gợi ý:
- Nếu dữ liệu nhỏ, <1000MB → dùng FAISS là đủ
- Nếu cần filter nâng cao, scale sau này → chọn Milvus qua Zilliz Cloud
☁️ Chọn giải pháp lưu trữ:
| Mục đích | Google Cloud Storage | Zilliz Cloud |
| Lưu trữ tệp (PDF, hình ảnh) | ✅ Rất tốt | ❌ Không phù hợp |
| Truy vấn vector | ❌ Không hỗ trợ | ✅ Rất mạnh, có API |
| Kết hợp trong RAG | Có thể dùng để lưu và ETL đầu vào | Tốt cho truy xuất vector |
✅ Gợi ý:
- GCS dùng để lưu trữ tệp nguồn
- Zilliz để lưu và truy vấn vector nhanh chóng
🚀 Chọn nền tảng Hosting ứng dụng RAG
| Lựa chọn | Gợi ý cho startup nhỏ |
| Local / VPS | Ubuntu + FastAPI hoặc Streamlit |
| Cloud đơn giản | Railway, Render, Fly.io |
| Scale lớn sau này | Google Cloud Run, AWS Fargate |
✅ Gợi ý: Dùng Streamlit hoặc FastAPI + hosting miễn phí ban đầu qua Render/Fly.io.
🧱 Tổng kết kiến trúc đề xuất và kết luận
- Dữ liệu gốc: PDF, hình ảnh, text (trên Google Cloud Storage hoặc server local)
- ETL: LlamaParse + Chonkie + OCR + Whisper
- Text embedding: Cohere embed-v3.0 (free tier)
- Image embedding: CLIP ViT-B/32 (local)
- Vector DB: FAISS (hoặc Zilliz Cloud nếu cần filter)
- LLM: GPT-4, Cohere, Gemini hoặc Claude (gọi API)
- Truy xuất: LangChain hoặc LlamaIndex
- Hosting: Streamlit hoặc FastAPI
🎯 Kết luận
Dù ngân sách hạn chế, bạn hoàn toàn có thể xây dựng một hệ thống RAG hiệu quả nếu chọn đúng công cụ:
- Tận dụng các free-tier hợp lý
- Dùng open-source khi cần
- Bỏ qua tính năng không cần thiết
- Tập trung vào phần lõi: dữ liệu, embedding và truy xuất