Trên trang TechNews, đã có nhiều bài viết về chủ đề RAG (Retrieval Augmented Generation). Nó là một hệ thống truy xuất và tích hợp thông tin liên quan từ các tài liệu bên ngoài để tăng cường kiến thức cho các mô hình ngôn ngữ lớn (LLM) trước khi chúng tạo ra câu trả lời, giúp cung cấp phản hồi chính xác và phù hợp với ngữ cảnh hơn. Hôm nay, tôi giới thiệu một cách xây dựng một ứng dụng sử dụng công nghệ RAG, kết hợp với công cụ có tên là LlamaIndex, để giúp các mô hình ngôn ngữ lớn có thể truy cập và sử dụng thông tin mới nhất hoặc dữ liệu riêng của doanh nghiệp của bạn.
Sau đây là nội dung bài viết trình bày gồm 5 phần. Bạn cũng có thể nghe dạng Podcast audio với nút nhấn dưới đây:
1. Vì sao cần RAG?
Các mô hình ngôn ngữ lớn (LLMs) hiện nay rất giỏi trong việc trả lời câu hỏi, viết văn, dịch thuật. Tuy nhiên, chúng có một hạn chế lớn: kiến thức của chúng chỉ giới hạn trong dữ liệu mà chúng đã được huấn luyện. Chúng không biết về những sự kiện xảy ra sau thời điểm huấn luyện, cũng như không thể truy cập dữ liệu cá nhân hay dữ liệu chuyên ngành của bạn. Khi gặp những câu hỏi đòi hỏi kiến thức chuyên sâu hoặc thông tin cụ thể không có trong dữ liệu huấn luyện, LLMs thường gặp khó khăn và đôi khi còn tạo ra thông tin sai lệch (gọi là “ảo giác” – hallucinations).
Vậy làm thế nào để “mở rộng kiến thức” cho LLMs? Có ba cách chính để LLMs có được kiến thức mới, nhưng đều có nhược điểm:
- Huấn luyện từ đầu (Training): Xây dựng một mô hình LLM mới từ đầu đòi hỏi lượng dữ liệu khổng lồ, sức mạnh tính toán cực lớn và chi phí lên tới hàng trăm triệu đô la. Điều này là không khả thi với hầu hết mọi người.
- Tinh chỉnh (Fine-tuning): Điều chỉnh một mô hình LLM đã có sẵn trên dữ liệu mới của bạn. Cách này đỡ tốn kém hơn huấn luyện từ đầu nhưng vẫn tốn nhiều thời gian và tài nguyên. Nó cũng không phải lúc nào cũng cần thiết trừ khi bạn có một yêu cầu rất đặc biệt.
- Nhắc lệnh (Prompting): Đặt thông tin mới vào cửa sổ ngữ cảnh (context window) khi bạn hỏi LLM. LLM sẽ dùng thông tin đó để trả lời. Tuy nhiên, cửa sổ ngữ cảnh của LLMs có giới hạn, và kích thước tài liệu thường lớn hơn giới hạn này. Do đó, cách này không đủ để xử lý các tài liệu dài.
Đây chính là lúc Retrieval Augmented Generation (RAG) phát huy tác dụng. RAG giải quyết những vấn đề trên bằng cách tạo ra một hệ thống tìm kiếm thông tin liên quan từ dữ liệu của bạn và đưa thông tin đó cho LLM trước khi nó tạo ra câu trả lời. Điều này giúp LLM trả lời chính xác hơn, dựa trên ngữ cảnh cụ thể của dữ liệu bạn cung cấp, mà không cần phải huấn luyện lại hay tinh chỉnh tốn kém.
2. Các thành phần chính của một hệ thống RAG
Một hệ thống RAG bao gồm nhiều bộ phận quan trọng làm việc cùng nhau:
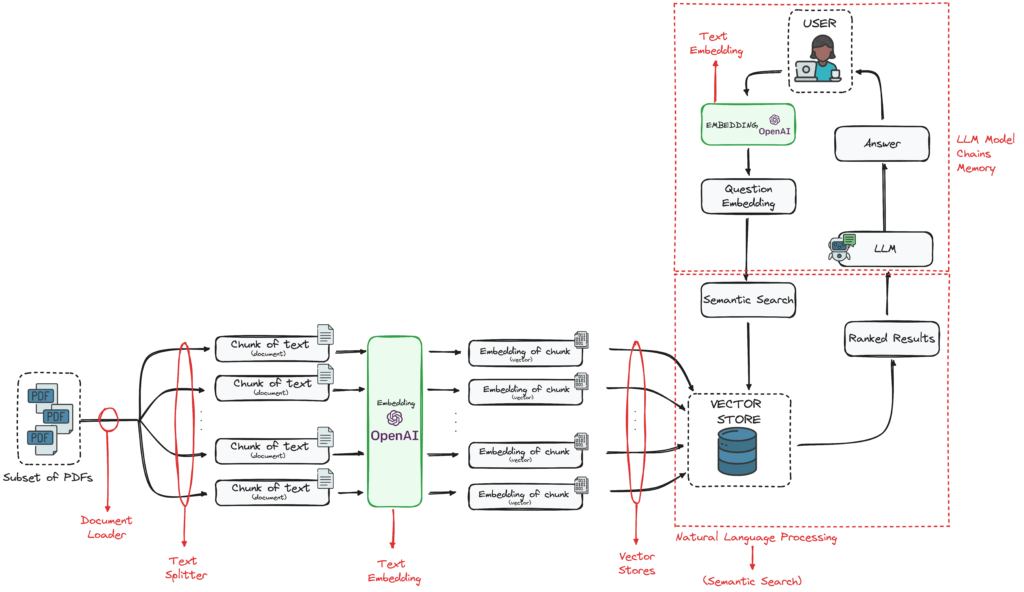
Hình 1: Kiến trúc tổng thể hệ thống RAG
- Text Splitter (Bộ chia văn bản): Công cụ này chia nhỏ các tài liệu lớn thành những đoạn văn bản ngắn hơn. Việc chia nhỏ này rất quan trọng vì LLMs chỉ xử lý được một lượng văn bản nhất định trong “cửa sổ ngữ cảnh” của chúng.
- Embedding Model (Mô hình nhúng): Chuyển đổi các đoạn văn bản thành biểu diễn dạng số (vector). Điều này cho phép máy tính hiểu được ý nghĩa của văn bản và thực hiện các phép tìm kiếm dựa trên sự tương đồng về ngữ nghĩa (tìm các đoạn văn bản có ý nghĩa gần giống nhau).
- Vector Store (Kho vector): Một loại cơ sở dữ liệu đặc biệt để lưu trữ các vector biểu diễn của văn bản cùng với thông tin liên quan (metadata). Kho vector giúp tìm kiếm các vector tương đồng một cách rất hiệu quả và nhanh chóng.
- LLM (Mô hình ngôn ngữ lớn): Đây là mô hình chính tạo ra câu trả lời. Nó nhận thông tin liên quan đã được tìm thấy từ kho vector và sử dụng nó để trả lời câu hỏi của người dùng.
- Utility Functions (Các hàm tiện ích): Bao gồm các công cụ khác như bộ đọc tài liệu (document parsers) hoặc công cụ truy cập web (web retrievers) để giúp chuẩn bị và lấy dữ liệu ban đầu.
Mỗi thành phần này đều đóng vai trò thiết yếu để hệ thống RAG hoạt động chính xác và hiệu quả.
3. LlamaIndex là gì?
LlamaIndex (trước đây là GPTIndex) là một framework (bộ công cụ) bằng Python được thiết kế riêng để giúp bạn xây dựng các ứng dụng sử dụng LLMs. Nó hoạt động như một cầu nối giữa dữ liệu riêng của bạn (tài liệu, cơ sở dữ liệu…) và các mô hình ngôn ngữ lớn.
LlamaIndex giúp bạn dễ dàng thực hiện các bước:
- Nạp dữ liệu (Data ingestion): Đưa dữ liệu của bạn vào hệ thống.
- Lập chỉ mục (Indexing): Tổ chức và xử lý dữ liệu (như chia nhỏ, tạo vector) để chuẩn bị cho việc tìm kiếm.
- Truy vấn (Querying): Đặt câu hỏi và lấy thông tin từ dữ liệu của bạn thông qua LLM.
LlamaIndex hỗ trợ sẵn nhiều nguồn dữ liệu khác nhau, các loại cơ sở dữ liệu vector và các cách để truy vấn. Nó được coi là một giải pháp “tất cả trong một” cho các ứng dụng RAG. LlamaIndex cũng có thể tích hợp dễ dàng với các công cụ phổ biến khác như LangChain, Flask, Docker, giúp nó rất linh hoạt trong thực tế.
4. Cách xây dựng một hệ thống RAG đơn giản với LlamaIndex
Đây là các bước cơ bản để triển khai một hệ thống RAG nhỏ sử dụng LlamaIndex, như được trình bày trong nguồn:
Bước 1: Cài đặt môi trường Trước tiên, bạn cần chuẩn bị môi trường Python của mình. Nên sử dụng môi trường ảo (venv) để quản lý các thư viện cần thiết. Bạn cần cài đặt các thư viện chính: llama-index, openai (để dùng mô hình OpenAI), và faiss-cpu (một công cụ tìm kiếm vector hiệu quả).
python -m venv rag_env
source rag_env/bin/activate # Hoặc rag_env\Scripts\activate trên Windows
pip install llama-index openai faiss-cpu
Sau đó, bạn cần thiết lập khóa API của OpenAI (hoặc các mô hình LLM khác) để LlamaIndex có thể kết nối và sử dụng mô hình của họ.
import os
os.environ[“OPENAI_API_KEY”] = “your-api-key-here” # Thay “your-api-key-here” bằng khóa API thật của bạn
Bước 2: Nạp tài liệu Để hệ thống có thể tìm kiếm, bạn cần đưa tài liệu của mình vào. LlamaIndex có công cụ SimpleDirectoryReader giúp đọc các tệp văn bản từ một thư mục. Ví dụ, bạn có thể đọc tất cả các tệp từ thư mục ./data.
from llama_index import SimpleDirectoryReader
# Nạp các tệp văn bản từ thư mục ./data
documents = SimpleDirectoryReader(“./data”).load_data()
print(f”Đã nạp {len(documents)} tài liệu”) # Sẽ in ra số lượng tài liệu đã nạp
(Ví dụ trong bài này sử dụng nội dung từ bài báo “Attention Is All You Need” để mở rộng kiến thức cho LLM).
Bước 3: Chia nhỏ văn bản Vì LLMs có giới hạn về lượng văn bản trong cửa sổ ngữ cảnh, bạn cần chia nhỏ các tài liệu đã nạp thành các phần nhỏ hơn và có cấu trúc tốt. Bạn có thể dùng SentenceSplitter để chia văn bản dựa trên câu.
from llama_index.text_splitter import SentenceSplitter
# Định nghĩa bộ chia văn bản dựa trên câu, với kích thước mỗi đoạn 512 ký tự và lặp 50 ký tự giữa các đoạn
text_splitter = SentenceSplitter(chunk_size=512, chunk_overlap=50)
# Áp dụng việc chia nhỏ cho nội dung của các tài liệu
nodes = text_splitter.split_text([doc.text for doc in documents])
print(f”Đã chia thành {len(nodes)} đoạn nhỏ”) # Sẽ in ra số lượng đoạn nhỏ
Bước 4: Lập chỉ mục (Indexing) với Embedding Để có thể tìm kiếm thông tin theo ý nghĩa (semantic search), bạn cần chuyển đổi các đoạn văn bản nhỏ thành vector biểu diễn và lưu trữ chúng trong một chỉ mục (index). LlamaIndex cung cấp VectorStoreIndex để làm điều này.
from llama_index import VectorStoreIndex
# Tạo một chỉ mục từ các đoạn văn bản nhỏ đã chia
index = VectorStoreIndex(nodes)
# (Tùy chọn) Lưu chỉ mục lại để dùng sau mà không cần tạo lại
index.storage_context.persist(persist_dir=”./storage”)
Bước 5: Truy vấn (Query) chỉ mục với RAG Đây là bước RAG hoạt động. Bạn sẽ sử dụng chỉ mục đã tạo để tìm kiếm các đoạn văn bản liên quan đến câu hỏi của bạn, và sau đó đưa các đoạn văn bản đó cho LLM để nó tạo ra câu trả lời cuối cùng.
from llama_index.query_engine import RetrieverQueryEngine
# Tạo công cụ truy vấn từ chỉ mục
query_engine = RetrieverQueryEngine.from_args(index.as_retriever())
# Đặt câu hỏi
response = query_engine.query(“What is attention?”)
# In câu trả lời
print(response)
Khi chạy đoạn mã trên với dữ liệu là bài báo “Attention Is All You Need”, bạn sẽ nhận được câu trả lời như sau (đã được LLM tổng hợp từ các đoạn văn bản liên quan được tìm thấy): “Attention là một cơ chế được sử dụng trong các mô hình học sâu để tập trung vào các phần liên quan của chuỗi đầu vào khi xử lý dữ liệu. Trong bài báo ‘Attention Is All You Need,’ tác giả Vaswani và các cộng sự đã giới thiệu kiến trúc Transformer, hoàn toàn dựa vào cơ chế tự chú ý (self-attention) thay vì các phương pháp lặp hay tích chập. Đổi mới chính là cơ chế tự chú ý, cho phép mô hình cân nhắc tầm quan trọng của các từ khác nhau trong một câu so với nhau, giúp xử lý song song tốt hơn và hiểu được các phụ thuộc ở khoảng cách xa.”
5. Kết luận
Xây dựng hệ thống RAG với LlamaIndex mở ra những khả năng mới thú vị để sử dụng LLMs vượt ra ngoài kiến thức huấn luyện ban đầu của chúng. Bằng cách tích hợp việc tìm kiếm tài liệu, lập chỉ mục dựa trên embedding và truy vấn theo thời gian thực, RAG giúp tăng độ chính xác và giảm “ảo giác”, làm cho nó trở thành một giải pháp mạnh mẽ cho các ứng dụng cần kiến thức chuyên ngành.
Với hướng dẫn từng bước này, bạn đã có một hệ thống RAG cơ bản hoạt động. Từ đây, bạn có thể mở rộng theo nhiều cách khác nhau:
- Sử dụng các mô hình embedding khác (như của OpenAI, Cohere, Hugging Face).
- Tích hợp với các cơ sở dữ liệu vector lớn hơn (như Pinecone, Weaviate, ChromaDB) để xử lý lượng dữ liệu lớn hơn.
- Triển khai hệ thống dưới dạng API (sử dụng Flask, FastAPI) hoặc giao diện chatbot.
- Tối ưu hóa cách chia nhỏ văn bản để cải thiện chất lượng tìm kiếm.
Bây giờ là lúc để bạn thử nghiệm, cải tiến và khám phá những gì có thể làm được với LlamaIndex!