Hệ thống RAG truyền thống (Retrieval-Augmented Generation) gặp khó khăn với dữ liệu hình ảnh, do không thể hiểu dữ liệu insights bên trong hình ảnh, biểu đồ, bảng biểu. Bài viết này giới thiệu một phương pháp sử dụng công nghệ nhúng đa phương thức của Cohere (multimodal embeddings) kết hợp với Gemini 2.5 Flash để tạo ra một hệ thống RAG có thể hiểu cả văn bản và hình ảnh. Điều này giúp hệ thống đưa ra câu trả lời chính xác dựa trên các biểu đồ, bảng biểu và hình ảnh trong tệp PDF.
Các bạn có thể nghe phiên bản Podcast audio của bài viết bằng cách nhấn nút sau:
Vấn đề: Điểm mù về hình ảnh của RAG truyền thống
Các hệ thống RAG truyền thống dựa vào việc nhúng văn bản (text embeddings) để tìm kiếm thông tin từ tài liệu. Nhưng điều gì sẽ xảy ra nếu những hiểu biết quan trọng nhất lại ẩn trong biểu đồ, bảng biểu và hình ảnh?
Khi phân tích các tệp PDF tài chính, báo cáo nghiên cứu đầu tư, hoặc slide trình bày thị trường, nhiều thông tin quan trọng nằm trong các yếu tố hình ảnh như:
- Phân tích số liệu trong biểu đồ tròn/cột (ví dụ: phân bổ danh mục đầu tư).
- Trực quan hóa xu hướng trong biểu đồ đường (ví dụ: hiệu suất thị trường).
- Dữ liệu có cấu trúc trong các bảng phức tạp (ví dụ: ma trận so sánh).
- Lưu đồ quy trình trong sơ đồ (ví dụ: kiến trúc hệ thống).
- Quan hệ không gian trong bản đồ hoặc bố cục.
Một cách tiếp cận chỉ dựa vào văn bản sẽ bỏ sót lớp thông tin quan trọng này.
Giải pháp: RAG Đa phương thức
RAG đa phương thức tăng cường RAG truyền thống bằng cách kết hợp khả năng hiểu văn bản và hình ảnh. Cách tiếp cận này cho phép:
- Tìm kiếm kết hợp hình ảnh + văn bản từ cùng một tài liệu.
- Một chỉ mục vector hợp nhất hỗ trợ nhiều loại dữ liệu (văn bản, hình ảnh).
- Gemini đưa ra các câu trả lời dựa trên ngữ cảnh, sử dụng cả văn bản hoặc hình ảnh đã tìm được.
Công nghệ chính
- Cohere’s Embed v4.0: Có thể nhúng cả văn bản và hình ảnh vào cùng một không gian vector.
- Gemini 2.5 Flash: Xử lý các câu hỏi cùng với ngữ cảnh (văn bản hoặc hình ảnh) để tạo ra câu trả lời thực tế, giống con người.
- FAISS: Lập chỉ mục và tìm kiếm các vector từ cả hai loại dữ liệu (văn bản và hình ảnh) một cách hiệu quả. FAISS hỗ trợ tìm kiếm láng giềng gần nhất xấp xỉ (approximate nearest neighbor) hiệu quả.
Quy trình làm việc End-to-End của RAG Đa phương thức
Dưới đây là luồng làm việc tổng thể của hệ thống RAG Đa phương thức:
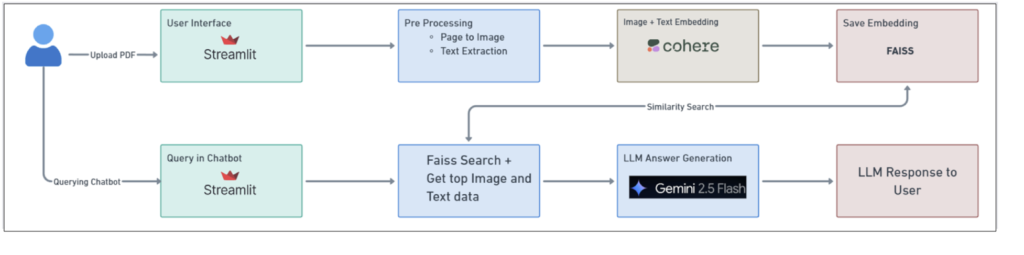
Hình 1: Luồng làm việc tổng thể của hệ thống RAG Đa phương thức
Từ việc tải tệp PDF lên đến việc nhúng hình ảnh/văn bản, tìm kiếm vector, và tạo câu trả lời bởi Gemini – mọi thứ được kết nối với nhau bằng Streamlit, Cohere, FAISS và Gemini 2.5 Flash.
Kiến trúc so sánh
- Kiến trúc RAG Đa phương thức: Trong quy trình này, cả văn bản và hình ảnh từng trang đều được nhúng bằng Cohere, lưu trữ trong FAISS, và được đưa làm ngữ cảnh cho Gemini 2.5 Flash. Điều này cho phép trả lời các câu hỏi dựa trên yếu tố hình ảnh – điều mà các thiết lập RAG truyền thống không thể xử lý.
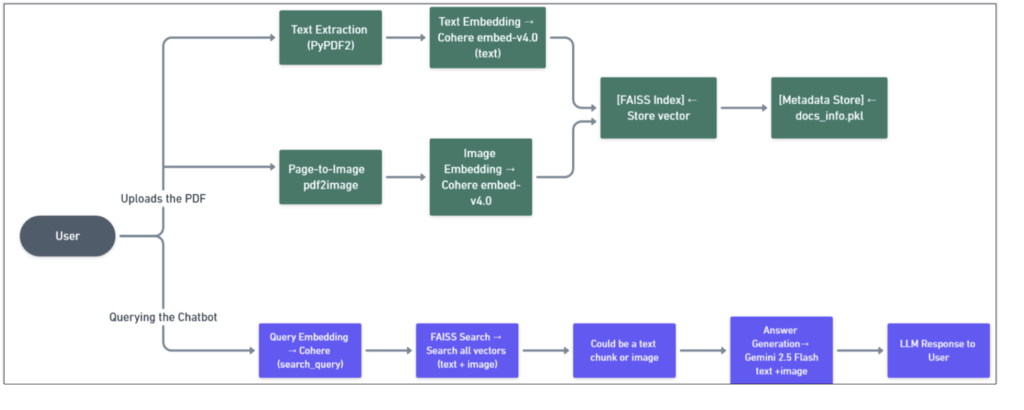
Hình 2: Kiến trúc RAG Đa phương thức
- Kiến trúc RAG chỉ dựa trên Văn bản: Cách tiếp cận này trích xuất văn bản từ PDF, nhúng nó, và sử dụng để tìm kiếm. Tuy nhiên, nó bỏ sót hoàn toàn thông tin được nhúng bên trong biểu đồ hoặc đồ họa.
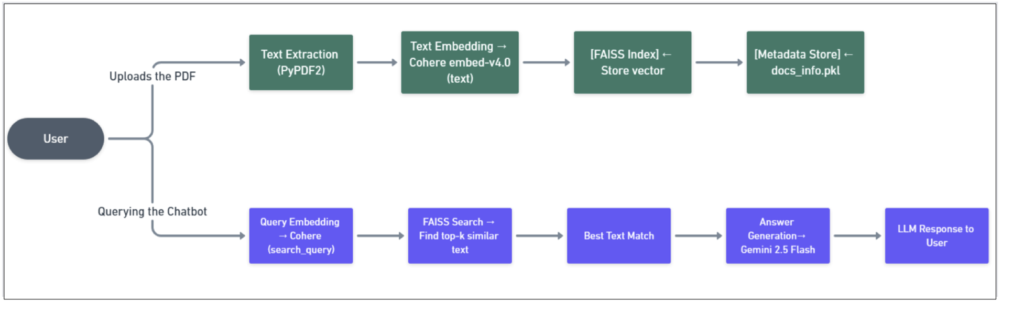
Hình 3: Kiến trúc RAG chỉ dựa trên văn bản
Kết quả: So sánh song song
Tôi đã thử nghiệm cả hai ứng dụng RAG chỉ dựa trên Văn bản và RAG Đa phương thức trên cùng một tài liệu PDF về ETF – Quỹ hoán đổi danh mục. Kết quả rõ ràng: RAG chỉ dựa trên Văn bản gặp khó khăn với các câu hỏi dựa trên dữ liệu hình ảnh, trong khi RAG Đa phương thức xử lý hiệu quả nội dung dựa trên hình ảnh.
Dưới đây là một số ví dụ:
| ❓ Câu hỏi | 📄 Ứng dụng chỉ văn bản | 🖼️ Ứng dụng đa phương tiện |
| Warren Buffett đã nói gì về ETF? | ✅ Trả lời từ phần giới thiệu văn bản | ✅ Kết quả tương tự |
| Tổng tài sản quản lý (AUM) của Invesco là bao nhiêu? | ❌ Bỏ sót (trong hình ảnh) | ✅ Lấy từ biểu đồ cột |
| BlackRock kiếm được bao nhiêu từ dịch vụ công nghệ? | ❌ Bỏ sót (trong biểu đồ) | ✅ Trả lời từ khối hình ảnh |
| Tỷ trọng của Apple trong S&P là bao nhiêu phần trăm? | ❌ Bỏ sót (biểu đồ tròn) | ✅ Trích xuất % từ hình ảnh |
| Trong đại dịch Covid, 10 cổ phiếu có tỷ trọng lớn nhất trong S&P 500 là gì? | ❌ Bỏ sót (biểu đồ dòng thời gian) | ✅ Phân tích từ infographic |
| Sự khác biệt giữa bong bóng Dotcom và cú sập do Covid là gì? | ❌ Bỏ sót (mất ngữ cảnh) | ✅ Diễn giải từ dòng thời gian trực quan |
| Làm thế nào để theo dõi Bitcoin trong các quỹ ETF? | ❌ Bỏ sót (dữ liệu bảng) | ✅ Diễn giải từ bảng dữ liệu |
Hướng dẫn mã nguồn: Xử lý Đa phương thức
1. PDF to Image Conversion
images = pdf2image.convert_from_path(pdf_path, dpi=200)
Sử dụng thư viện pdf2image, bạn có thể chuyển đổi các trang PDF thành danh sách các hình ảnh PIL. Danh sách này sau đó được sử dụng để nhúng.
2. Embedding with Cohere
if content_type == “text”:
response = cohere.embed(input_type=”search_document”, texts=[text])
else:
base64_img = convert_image_to_base64(image)
response = cohere.embed(
input_type=”search_document”,
inputs=[{“content”: [{“type”: “image”, “image”: base64_img}]}]
)
Nhúng với model Cohere, kiểm tra loại nội dung là “text” hay không. Nếu là hình ảnh, nó sẽ chuyển đổi ảnh sang định dạng base64 trước khi gửi đến API Cohere để nhúng.
Kết quả là vector float32 được thêm vào FAISS.
3. Gemini Answering Logic
if isinstance(content, Image.Image):
response = gemini.generate_content([query, content])
else:
response = gemini.generate_content(f”Question: {query}\n\nContext: {text}”)
Gemini nhận đầu vào là câu hỏi và nội dung (có thể là hình ảnh hoặc văn bản). Nó được thiết kế để phân tích biểu đồ, tiêu đề và bố cục một cách thông minh.
🚀 Bắt đầu – Ví dụ đơn giản
Đây là một đoạn mã ngắn gọn giúp bạn bắt đầu với RAG đa phương thức sử dụng Cohere + Gemini. Đoạn mã này bao gồm khởi tạo API, chuyển PDF thành ảnh, tạo embedding, index vector vào FAISS và logic trả lời câu hỏi đơn giản.
import cohere
from google.generativeai import GenerativeModel
import faiss
import numpy as np
from pdf2image import convert_from_path
from PIL import Image
# Initialize APIs
co = cohere.Client(“your-cohere-key”)
gemini = GenerativeModel(“gemini-2.5-flash”)
# Convert PDF page to image
def pdf_to_images(pdf_path):
return convert_from_path(pdf_path, dpi=200)
# Create embeddings
def get_embedding(content, content_type=”text”):
if content_type == “text”:
response = co.embed(input_type=”search_document”, texts=[content])
else:
base64_img = Image.open(content).resize((512, 512)).tobytes().hex()
response = co.embed(
input_type=”search_document”,
inputs=[{“content”: [{“type”: “image”, “image”: base64_img}]}]
)
return response.embeddings[0]
# Index and query
dimension = 1024
index = faiss.IndexFlatL2(dimension)
images = pdf_to_images(“your.pdf”)
for img in images:
index.add(np.array([get_embedding(img, “image”)], dtype=np.float32))
def answer_query(query):
query_emb = get_embedding(query)
D, I = index.search(np.array([query_emb], dtype=np.float32), k=1)
result = images[I[0][0]]
return gemini.generate_content([query, result]).text
⚙️Thiết lập dự án
Những gì bạn cần:
- 🔑 API Keys:
- Cohere embed-v4.0 → Create Cohere Account
- Gemini 2.5 Flash → Try Gemini on Google AI Studio
- 💻 System Requirements:
- Python 3.8+
- Poppler (for PDF image conversion)
- Cấu trúc tệp:
| File | Purpose |
| app.py | Streamlit UI for uploading, querying |
| core/embeddings.py | Calls Cohere for text/image embeddings |
| core/document_utils.py | PDF parsing, image conversion, FAISS indexing |
| core/search.py | Embedding-based search + Gemini response |
| config.py | API Keys & Model Settings |
Hạn chế và Cân nhắc
Mặc dù RAG đa phương thức mang lại nhiều lợi ích đáng kể, hãy lưu ý đến một số điểm sau:
- Chi phí tính toán: Xử lý và nhúng hình ảnh đòi hỏi nhiều tài nguyên hơn.
- Chi phí API: Các API nhúng đa phương thức thường tốn kém hơn so với API chỉ văn bản.
- Phụ thuộc vào chất lượng OCR: Việc nhận dạng văn bản trong biểu đồ vẫn phụ thuộc vào chất lượng của công nghệ OCR.
- Ảnh hưởng của độ phân giải hình ảnh: Hình ảnh có độ phân giải thấp có thể làm giảm chất lượng nhúng.
- Thử thách với hình ảnh phức tạp: Các hình ảnh trực quan hóa rất phức tạp có thể vẫn bị hiểu sai.
Lời kết
Nếu bạn đang phát triển ứng dụng LLM để hỗ trợ hỏi đáp tài liệu tài chính, trợ lý nghiên cứu hay phân tích tuân thủ, thì không chỉ cần xử lý văn bản mà còn cần xử lý cả hình ảnh. RAG đa phương thức giúp truy xuất thông tin một cách phù hợp với ngữ cảnh, bao gồm cả nội dung hình ảnh, và được thiết kế tối ưu cho LLM. Nhờ đó, nó có thể khai thác thông tin từ toàn bộ tài liệu của bạn, không chỉ từ phần văn bản.